
Ultimate Guide to RAG for Enterprise: Use Cases, Platforms, and Production Best Practices
ARTIFICIAL INTELLIGENCE.
Retrieval Augmented Generation (RAG) is one technique to overcome these issues. It combines LLMs with intelligent search to fetch data from indexed, governed data sources for more accurate and relevant outputs.
Due to its business value, the global RAG market volume is at $1.92 billion and is projected to grow to $10.20 billion by 2030, at a CAGR of 39.66% from 2025 to 2030. The rapid growth demonstrated RAG's key value in helping businesses use LLMs to build trustworthy, factual, and secure AI applications.
In this guide, we’ll explain why RAG matters and its key components. We will explore RAG use cases, platform options, and how Aplyca, as an AWS Partner, can help you build a multi-tenant RAG system tailored to your needs.
What is RAG, and Why Does RAG Matter Now?
Although the term "RAG" may be unfamiliar to everyone, it is already widely used in many AI tools we interact with regularly. Whenever an LLM searches the web (like ChatGPT's web search option), scans a PDF you upload, or answers a question using a document you give, it uses RAG-like retrieval augmentation to generate responses.
RAG operate in three key stages:
Retrieval: The system uses the query to search an external trusted source, such as databases, research papers, or enterprise knowledge bases. This “retriever” component identifies and pulls the most relevant snippets of information.
Augment: The retrieved context is then combined with the original user query into a new, more detailed prompt.
Generation: This augmented prompt is fed to the LLM, which uses the provided information to generate a grounded, contextually-aware response.
RAG helps LLMs to ground their responses in authoritative and predetermined knowledge sources such as your company's proprietary data. Without it, LLMs tend to give incorrect information when they don’t know the right answer, generate outdated responses, or craft false details on their own, citing unreliable sources.
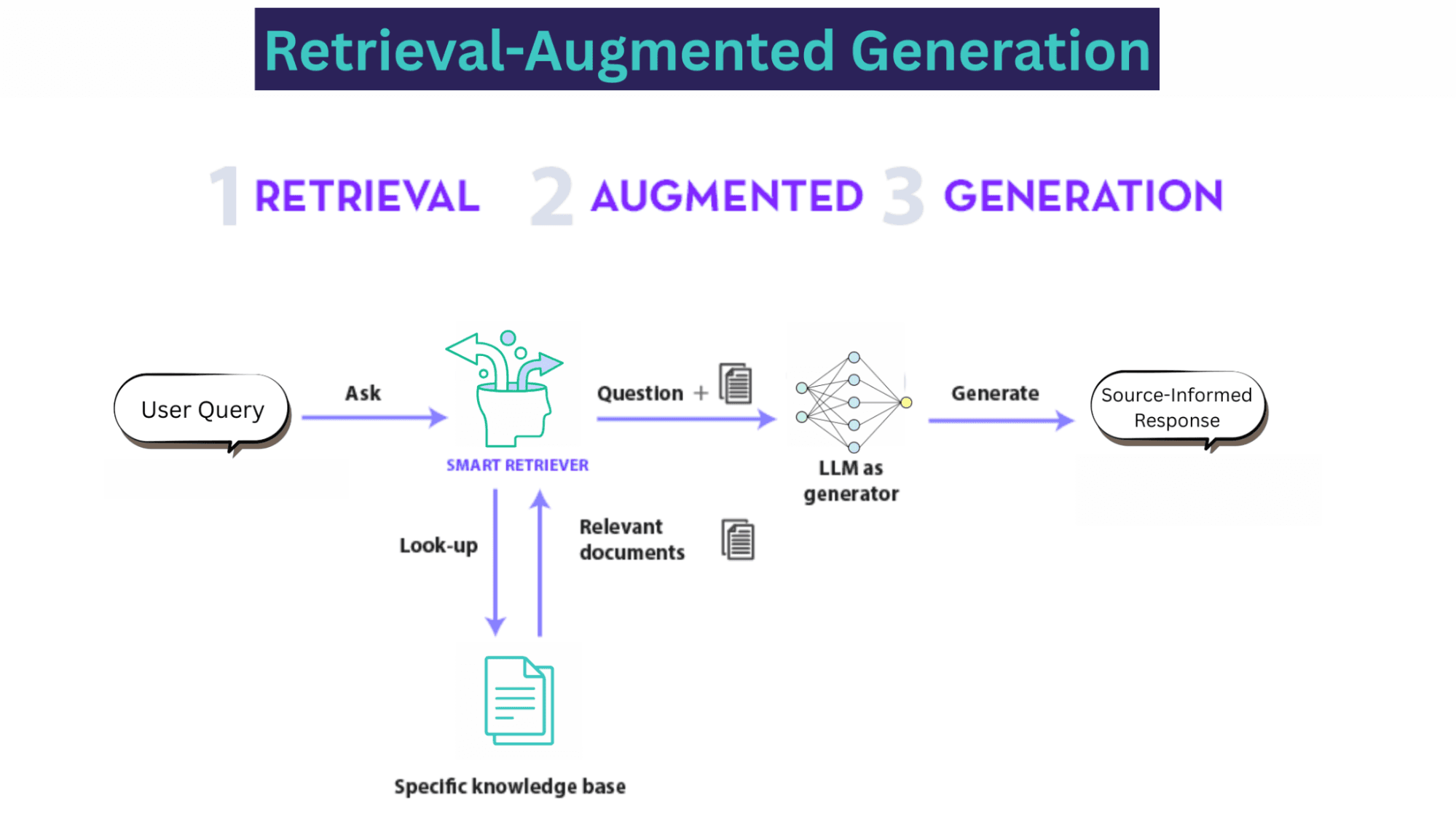
A representative instance of the RAG process applied to question answering. | Source
However, with advanced models like the latest versions of Google’s Gemini Pro and Claude Sonnet, the AI community is starting to question RAG’s relevance in the near future. Let’s try to address the debate head-on.
Why Do We Still Need RAG?
Latest models come with larger context windows, more up-to-date knowledge, and better safeguards to prevent them from generating false or harmful responses. These features often lead users to think that RAG isn’t relevant anymore.
However, such features introduce trade-offs in latency, cost, and performance when processing millions of tokens per query. As a result, LLMs become slower and more expensive.
For instance, longer context windows may allow LLMs to process more information simultaneously. However, the processing load increases. Additionally, it is challenging to verify the information since the user lacks control over the sources the model utilizes.
In contrast, RAG allows businesses to cheaply leverage an LLM's pre-trained knowledge on an industry-specific task. Users can build a carefully curated knowledge base, allowing the RAG system only to fetch relevant data from it instead of searching the entire web.
Plus, with the help of agentic AI, RAG frameworks can reason which knowledge base to look for based on a user's query. As a result, RAG enables LLMs to utilize new knowledge and comply with relevant regulatory standards. Businesses don't have to go through an entire phase of re-training or fine-tuning to update a model as user requirements change.
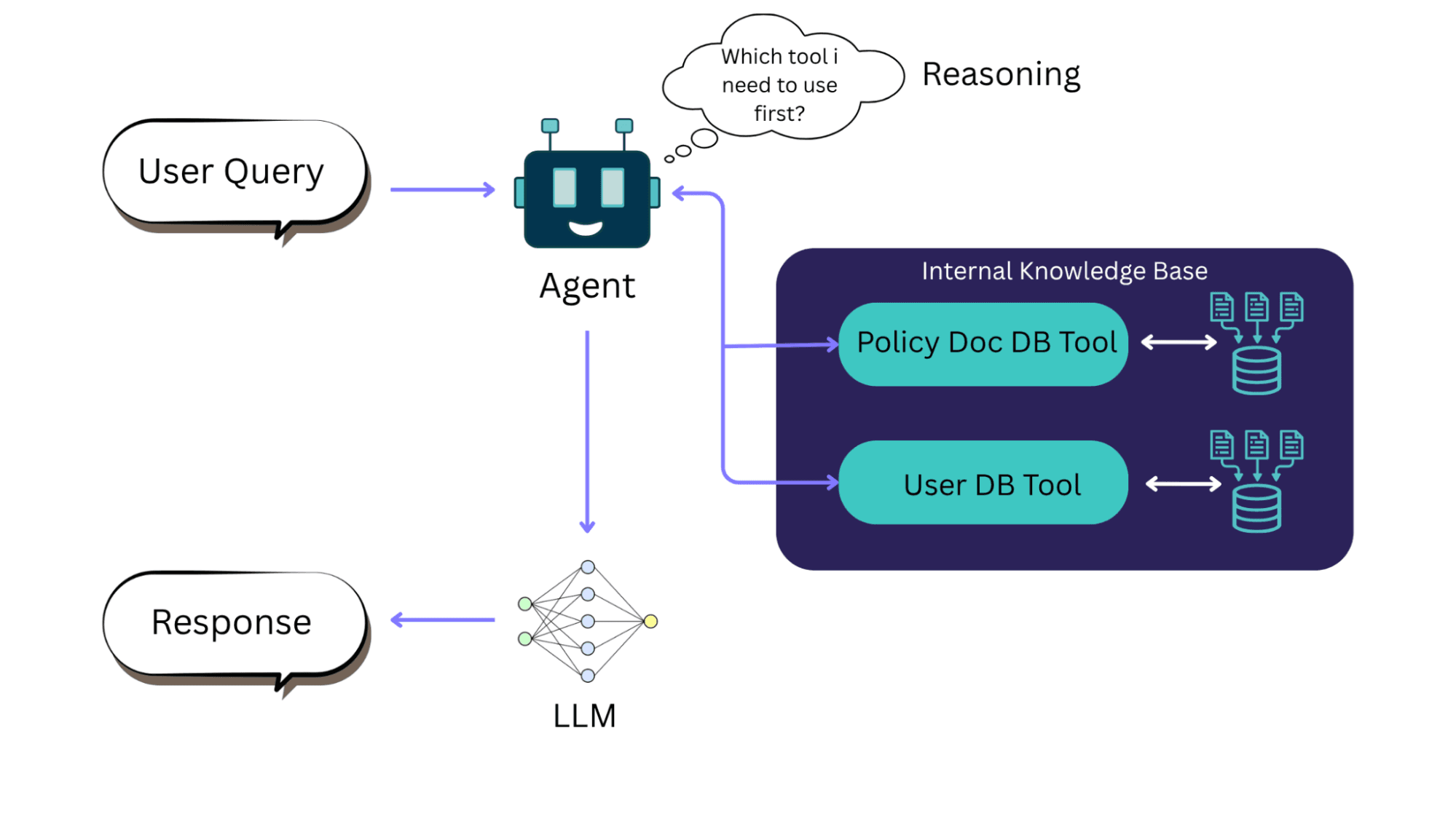
RAG with AI agent | Source
RAG Use Cases: Where It Delivers Impact in the Enterprise
RAG is not a monolithic solution, but it helps drive value across numerous business functions. Enterprises can use their data to turn generic generative AI into value-driven tools.
Digital and Customer Experience
RAG's immediate impact is in transforming a brand's digital and customer experience. It provides hyper-personalized responses to user queries, whether for pre-sales questions or 24/7 technical support. It does this by retrieving context from a use-case-specific knowledge base built from a company's product specs, manuals, and internal documentation.
Moreover, businesses can create a dynamic feedback loop to record customer complaints, queries, reviews, and support tickets, and feed this data back into the RAG system. It can help the system get smarter and more accurate over time as more users interact with it.
Integrating RAG with the content platforms that businesses already use brings digital experiences to life. Here’s how it is applied to some leading platforms:
RAG with Adobe Experience Manager (AEM): AEM is a large-scale platform for managing digital content and assets. Using RAG with AEM lets companies access a huge library of content and user data, which enables personalized and conversational experiences that stay consistent with the brand's messaging.
RAG with Contentful: It is an API-first headless CMS that delivers content to various channels. Integrating RAG with Contentful can create omnichannel strategies that provide intelligent responses across websites, mobile apps, and internal tools, all pulling from the same trusted content source. We at Aplyca applied the same principle to create an omnichannel web platform for Vanti Business Group, proving how a well-architected Contentful solution unifies a complex digital ecosystem.
RAG with Ibexa DXP: Ibexa DXP manages product catalogues and partner-facing content with a strong focus on B2B scenarios. RAG is powerful here for building next-gen conversational commerce solutions that help B2B customers navigate product lines and receive expert guidance through automated conversations. At Aplyca, we leveraged Ibexa DXP to modernize Terpel's corporate portal, integrating chatbots, multilingual support, and key modules like georeferencing to deliver a stable, scalable digital experience aligned with multi-country operations.
RAG with Payload CMS: Payload is a developer-focused headless CMS known for its flexibility and deep customization. Integrating RAG with Payload is perfect for building bespoke, cutting-edge AI applications where developers need granular control to fuse unique content models with advanced conversational AI features.
Content Production and Management
RAG speeds up internal content workflows for global companies. It automates updating knowledge bases by creating summaries and FAQs from long reports and makes information current and easy to search. RAG also simplifies multilingual publishing by using approved terminology for translations, which ensures brand and technical consistency across all languages.
Business Process Automation
RAG streamlines internal operations by automating knowledge retrieval from dense corporate documents. It helps legal teams quickly check thousands of pages of contracts or allows compliance officers to look up specific rules like GDPR.
Additionally, it acts like a virtual assistant for all employees, providing accurate answers from HR manuals and technical guides, saving time that would otherwise be spent searching through messy intranet sites.
Building the RAG Stack: A Guide to Enterprise Platforms and Frameworks
Selecting the appropriate technology stack is a crucial choice that factors in speed, flexibility, capital, and control. We can assemble RAG pipelines using either cloud-native managed services or flexible open-source frameworks.
The major cloud providers offer integrated, managed services that significantly speed up the development and deployment of RAG applications.
For instance, Amazon Web Services offers Amazon Bedrock's Knowledge Bases that connect corporate documents (from an S3 bucket) to LLMs. It uses Amazon OpenSearch Service or other vector stores for indexing and provides managed infrastructure, autoscaling, and easy integration with other cloud services.
Similarly, Microsoft’s Azure AI Search provides integrated vector search capabilities that connect with Azure OpenAI, allowing you to ground models in your own data sources. And Google's Vertex AI Search with its RAG Engine connects to enterprise data in sources like BigQuery and Cloud Storage to keep model outputs accurate and aligned with your information.
Alternatively, we can use open-source frameworks for greater flexibility (like building multi-cloud RAG pipelines) and to avoid vendor lock-in. They may include:
Orchestration Frameworks like LangChain and LlamaIndex to help structure the RAG pipeline, from loading documents to prompting the LLM.
Cloud vs. Agnostic: The Enterprise Dilemma
The choice between a managed cloud-native stack and an open-source solution is a critical strategic decision because there is no one-size-fits-all answer.
The table below shows the critical factors to consider when choosing between the two.
Factor | Cloud-Native | Agnostic / Open-Source |
Time-to-Market | Faster. Tightly integrated, managed services greatly reduce development and deployment time. | Slower. Requires more time for setup, integration, and manual configuration of individual components. |
Cost Structure | Consumption-Based (OpEx). Predictable, pay-as-you-go pricing, but it can become expensive at a very large scale. | Infrastructure and Talent-Based (CapEx/OpEx). Lower direct software costs, but requires significant investment in skilled in-house talent and infrastructure management. |
Flexibility & Control | Less Flexible. You are limited to the provider's ecosystem and component choices. Customization can be constrained. | Highly Flexible. Complete freedom to mix-and-match best-of-breed models, databases, and frameworks. No vendor lock-in. |
In-House Expertise | Lower Requirement. Abstracts away much of the complex infrastructure management, requiring less specialized MLOps/DevOps knowledge. | Higher Requirement. Demands a strong in-house team with deep expertise in DevOps, MLOps, Kubernetes, and data engineering. |
Maintenance & Scaling | Managed. The cloud provider handles security patches, updates, and scaling, ensuring high availability and reliability. | Self-Managed. Your team is fully responsible for all maintenance, security, and scaling operations. |
Best For | Enterprises prioritizing speed, ease of use, and using an existing cloud investment to get a reliable solution to market quickly. | Enterprises with unique customization needs, a strong in-house technical team, and a strategy to avoid vendor lock-in at all costs. |
Advanced RAG Techniques
As organizations mature beyond baseline retrieval, Advanced RAG architectures aim to improve recall, relevance, reasoning depth, and traceability. These techniques combine innovations from search, graph theory, and multi-agent reasoning to create AI systems that understand context rather than merely retrieve it.
Hybrid and Multi-Stage Retrieval
Modern enterprise data is heterogeneous, mixing structured databases, documents, and media. A hybrid retrieval strategy merges symbolic search (BM25, keyword) with dense vector search (semantic embeddings).
Lexical Filter: Fast keyword or metadata search narrows the corpus.
Dense Retrieval: Semantic vectors rank contextual proximity.
Cross-Encoder Re-ranking: A smaller transformer re-scores top results for semantic accuracy.
This three-tier pipeline typically improves contextual precision by 15–25 % without significant latency overhead.
HyDE (Hypothetical Document Embeddings)
Hypothetical Document Embeddings (HyDE) enhances retrieval by generating a hypothetical ideal answer to a query before searching. This "pseudo-document" is then embedded and used for retrieval, leading to higher recall, particularly in sparse datasets or when source terminology differs.
HyDE is especially valuable for enterprise knowledge bases, which often contain semi-structured data like policies, FAQs, and PDFs, as it effectively bridges vocabulary gaps. It integrates seamlessly with OpenSearch + AWS Bedrock or LangChain retrievers. While it introduces a slight latency increase of approximately 100–200 ms, this is a small trade-off for the notable improvement in recall quality.
Graph RAG
Graph RAG utilizes knowledge graphs to represent entities (e.g., people, products, regulations) and their relationships, storing this information in databases like Neo4j, AWS Neptune, or RDF-compatible engines. This approach allows retrieval to navigate complex graph paths instead of relying on flat text.
Capability | Benefit |
Entity Linking | Prevents duplication and resolves alias ambiguities. |
Relationship Traversal | Enables advanced multi-hop reasoning, allowing queries like "Who approved what and why?" |
Provenance Tracking | Facilitates tracing answers back to their original nodes for compliance and auditing. |
Graph RAG is particularly valuable for applications such as regulatory audits, supply-chain traceability, pharmaceutical research, and managing corporate taxonomies. For even more robust grounding, combine graph context with vector embeddings in a hybrid approach (Graph + RAG).
Multi-Vector and Late-Interaction Models
Unlike traditional RAG, which embeds an entire document as a single dense vector, multi-vector retrieval (e.g., ColBERT, CoVeR, ANCE) individually encodes each sentence or token. This approach enables late interaction scoring, where query and document vectors are compared after the initial retrieval phase.
Benefits include improved handling of complex documents, enhanced semantic coverage, and increased precision, which delivers higher accuracy for question answering over specialized texts such as legal or technical documents.
Reranking and Fusion Retrieval
For large repositories, initial retrieval often mixes relevant and noisy results. A reranking stage applies a cross-encoder model (e.g., BGE-Reranker, MonoT5) to refine ordering. Fusion retrieval aggregates multiple retrievers (dense, lexical, graph) through weighted voting or reciprocal rank fusion (RRF).
This hybrid ensemble consistently improves Top-k accuracy (the probability that correct evidence appears in the first k results) by 20–40 %.
Memory-Augmented RAG
Enterprises using conversational copilots require session persistence. Memory-Augmented RAG addresses this by storing past interactions as retrievable embeddings, creating a short-term semantic memory.
Memory-Augmented RAG include customer-support agents who need to maintain case context, onboarding assistants that recall previous topics, and personalized marketing copilots that remember user history.
Agentic RAG (AI Orchestration Layer)
The newest frontier merges RAG with autonomous reasoning. Agentic RAG allows the model to plan multistep retrievals, verify results, and call tools or APIs dynamically. Powered by orchestration frameworks (LangGraph, DSPy, AutoGen, or AWS Bedrock Agents), these systems can:
Formulate sub-queries
Retrieve & validate facts
Synthesize multi-document insights
Produce an auditable reasoning chain.
Enterprise Impact includes transforming static knowledge retrieval into dynamic decision-support workflows, enhancing explainability by logging each reasoning step and its source, and facilitating governed cross-system orchestration (CRM, CMS, ERP).
RAG Best Practices for Production Readiness
Transitioning to a production-ready RAG system requires scalable architecture, continuous evaluation, and strong security from the start. To go live with a RAG system, consider these best practices:
Start Simple, Iterate Relentlessly: Do not try to implement a complex, multi-agent pipeline from day one. Begin with a basic pipeline (embed-docs + BM25 or single-vector retriever + LLM) and stabilize it. Then incrementally add complexity (rerankers, hyde, etc.) based on need.
Plan for Multilingual and Multi-Tenancy Early: If your enterprise serves multiple languages or distinct customers, design for it upfront. For multilingual support, consider using multilingual embedding models or maintaining separate indexes for each language. For multi-tenancy (a SaaS platform), plan data isolation and per-tenant indexing from the start. Use AWS per-tenant S3 buckets and encryption to isolate data. Attempting to add these later can require costly re-architecture.
Security and Compliance First: You need to treat RAG like any other sensitive data project and encrypt all vector stores at rest, use key rotation, and implement strict IAM so that only authorized roles can query or index data. Ensure that your RAG logs are auditable (which source docs were used for each answer). All content pipelines should sanitize input and output ( if user inputs are used in prompts).
Partner for Expertise: Given the complexity, consider working with a specialist like Aplyca. Deploying a robust RAG system involves AI, DevOps, data engineering, and security, so having an experienced partner can help accelerate progress and enforce best practices.
How Aplyca Delivers a Multilingual, Multi-Tenant RAG Pipeline for a Global Enterprise
Building, deploying, and maintaining an advanced, enterprise-grade RAG pipeline is more of an engineering feat that requires expertise in data architecture, cloud infrastructure, DevOps, and security.
The Challenge
Consider a global financial services firm with offices in North America and Europe. They want to give their advisors real-time, compliant answers from a vast and constantly changing collection of internal reports, analyst notes, and regulatory documents. But they face some challenges:
Data Security: The system must enforce strict data segregation. Advisors working in wealth management shouldn’t access information from investment banking.
Scalability: It needs to work well even when thousands of advisors ask questions at the same time.
Multilingual Support: It needs to serve both English and Spanish-speaking teams with high accuracy.
The Aplyca Solution
We at Aplyca solve these kinds of problems. We architect a solution that is secure, scalable, and resilient by design using our deep expertise in DevOps and as an AWS Partner.
Compliance-First Design: We design a secure multi-tenant RAG pipeline. Using AWS services, we implement a data governance model with advanced data isolation so each division's data is kept apart, both logically and physically. This way, no one can access the other team’s information, which keeps everything compliant and secure.
DevOps and MLOps Excellence: With DevOps expertise, we built an automated MLOps pipeline for the RAG system with infrastructure as code (IaC) for repeatable environments, CI/CD for the AI components, and strong monitoring and logging.
Built to Grow: Using scalable AWS services and serverless functions, the system is designed to handle large workloads from the start. It can automatically support thousands of users at the same time without slowing down, providing a smooth experience for every advisor.
This system transforms the company's specialized knowledge into a valuable asset. Advisors benefit from rapid, reliable answers, enhancing their productivity and decision-making. Consequently, the firm gains a competitive advantage while upholding security and regulatory compliance.
Ready to make your enterprise knowledge truly intelligent? Aplyca designs and implements RAG-powered digital experience architectures on AWS and composable platforms like Contentful, Ibexa DXP, PayloadCMS and Adobe AEM.
Contact us to discuss how RAG can power your next generation of AI-driven digital experiences.