
Semantic Search - A New Step in Digital Experience
USER EXPERIENCE, TECHNOLOGY OF EXPERIENCE.
When we use websites and click on the small magnifying glass to start a search, we face three possibilities: to be lucky and find what we are looking for, to get zero results because our keyword does not exist, or to receive hundreds of irrelevant results when we include several words.
Interest in semantic search has resurfaced due to the excitement generated by recent advances in Generative Artificial Intelligence (Generative AI) and a certain idealization of its capabilities. Its potential lies in enabling much more satisfying search experiences on private web and e-commerce platforms, using technologies that were previously exclusive to technology giants like Google, Netflix, or Spotify.
What is semantic search?
"Semantics" is a linguistic discipline that focuses on the study of meaning and understanding of language. It analyzes how words, phrases, and sentences represent different concepts and meanings in different contexts.
Semantic searches aim to capture the meaning and intention of a search rather than simply matching keywords.
Bags of words - Non-semantic search
When we use a search engine like Elastic Search and Solr we are using a bag-of-words model. This bag is created by ignoring common words (stop-words), stemming words, and storing them in an index, known as a sparse vector. When making a query, algorithms are used that find the words and assign them a score to know how to order the results. The algorithms rank according to how present the word is in the found document vs. how scarce or abundant it is in the rest of the documents. For example, if it appears several times in the found document and is scarce in the rest of the documents, we have a winning result. The algorithms themselves are relatively easy to understand, and it can be interesting to explore the history and functioning of algorithms such as TF-IDF and BM25, although they do not significantly change the search model.
Bag-of-words searches are very effective when there is a strong correlation between what we are looking for and the document's index. If we search for the word "dog", and the document prominently features it compared to the rest: wonderful! That's why this type of model is ideal for direct, precise searches, ideally with few terms. When we have many more terms, with synonyms, word derivations, and other implicit meanings, we arrive at the dreaded "zero search results".
Semantic searches
Semantic searches allow finding relevant similarities in a data set. Instead of looking for exact matches of keywords - as in a bag-of-words search - semantic searches allow search engines to identify elements that are semantically similar to the user's search query.
To achieve vector searches in which a word or content is represented with its meaning, vector spaces and embeddings are necessary. In simple terms, an embedding is a numerical (vector) representation of a text object (like a word or phrase). These embeddings are generated in such a way that words or phrases with similar meanings are closer to each other in the vector space. The magic happens with natural language processing and machine learning techniques, which are trained with large datasets to learn the subtleties of language and the content with which they were trained.
The search engine transforms the user's query into a vector (also known as embedding), and looks in its database for other vectors that are similar. Similarity is generally measured using a distance metric in the vector space, and they return results ordered by similarity without having to exactly match.
Vector searches are capable of capturing the subtleties and semantics of language, achieving more relevant searches. For example, a vector search would be able to understand that a search query for "dog" could return results about "animals", "Dachshund", "Labrador".
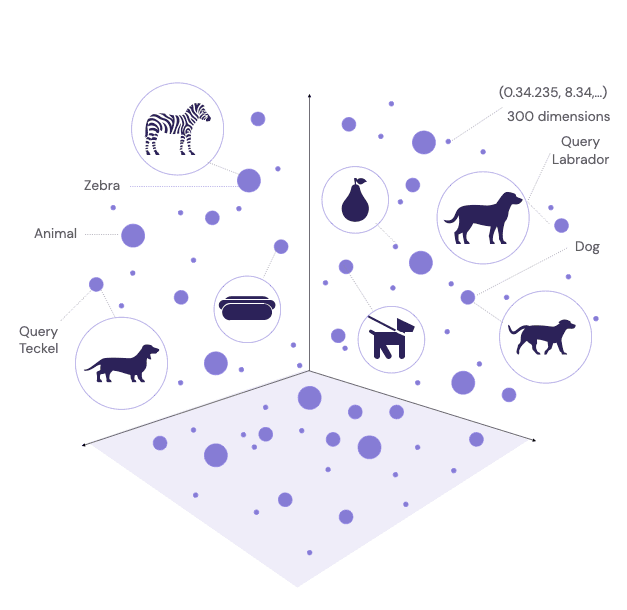
Figure 1: Simplified vector representation of various concepts
Vector engines help store large amounts of data to understand context, user intent, and the relationships between different concepts, all of which are crucial for providing accurate and personalized search results.
In 2023, vector databases for storing and searching over vectors have started to take the spotlight. Some of these, like Pinecone and Weaviate, have hybrid search models where the same search is made with bag-of-words and semantic methods, allowing for combining the results. It's worth exploring these platforms further:
Vector databases for semantic search
Tool | Prominent Users | DB Features | Embedding mgmt | SQL-like filtering | Full text search |
|---|---|---|---|---|---|
Chroma | N/A | ✓ | ✓ | ✓ | 𐄂 |
Milvus | ebay, Walmart | ✓ | 𐄂 | ✓ | 𐄂 |
Pinecone | Shopify, Gong | ✓ | 𐄂 | ✓ | 𐄂 |
Vespa | Yahoo, Spotify | ✓ | ✓ | ✓ | ✓ |
Weaviate | N/A | ✓ | ✓ | ✓ | ✓ |
Table 1: Taken from the lecture by Josh Tobin. Published on May 9, 2023
Pinecone
This is a service that focuses on semantic vector search, commonly used to integrate machine learning functionalities into applications. Pinecone facilitates the indexing and search of high-dimension vectors on a large scale. It is particularly useful in contexts requiring vector representations for information retrieval.
Weaviate
This is a database system that combines semantic and vector functions. It uses machine learning techniques for the semantic search and sorting of data. Weaviate stands out for its ability to perform contextual and semantic searches, thanks to its vector-based classification engine.
Chroma
This is an open-source embeddings database that facilitates the creation of LLM applications by making knowledge, facts, and skills easily integrable. It allows storing embeddings and their metadata, embedding documents and queries, and searching for embeddings.
Milvus
This is an open-source vector database designed for large-scale similarity searches. It allows working with several distance metrics, including Euclidean distance and cosine similarity. It also offers options to customize indexing and is compatible with machine learning applications. This versatility makes it an excellent option for tasks that require vector representations for information retrieval.
Vespa
This is a real-time search and information retrieval engine, created by Yahoo. Its strength lies in handling searches in both text and vector representations of data. Vespa can index large volumes of data and deliver search results efficiently. It also allows for the definition and calculation of custom functions to rank documents at the time of the query.
Nomic Atlas
This is in a special category. Created by Nomic.ai, it has a very interesting approach: it combines an embeddings generator, a semantic database, and an online viewer for millions of data. Visualize and interact with large data sets, collaborate in their cleaning and labeling, develop high availability applications with semantic search and understand the latent space of AI models.

NOMIC, Data Exploration
Imagining the semantic proximity of two contents is challenging but their visualization tool summarizes the result of the embeddings vectors in a bi-dimensional space. Nomic Atlas demos are impressive, grouping millions of tweets without affecting the performance of the viewing machine. The platform is evolving rapidly, and Nomic has a strong development team. In June 2023, the viewer works well on desktop, but on mobile it is still very limited. Their free plan allows easy data exploration, and their documentation has good examples for implementation.
Semantic Embeddings - The magic of where semantic relationships come
Semantic embeddings are a way of representing words as vectors in a high-dimensional space, where words with similar meanings are located near each other. This technique has been used in natural language processing tasks, such as text classification, information retrieval, and language translation.
OpenAI Embeddings
The OpenAI Embeddings service, which uses the text-embedding-ada-002 model behind the scenes, is an attractive option in terms of price and quality. Although OpenAI is widely known for ChatGPT, the embeddings service uses an engine much less powerful than GPT-4, but considerably potent and very efficient in terms of price.
Cohere Embeddings
Cohere is an innovative Canadian firm that has created its own Generation, Classification and Semantic Search engines. Cohere has multi-language embedding engines with auto detection as well as single-language ones with different capabilities.
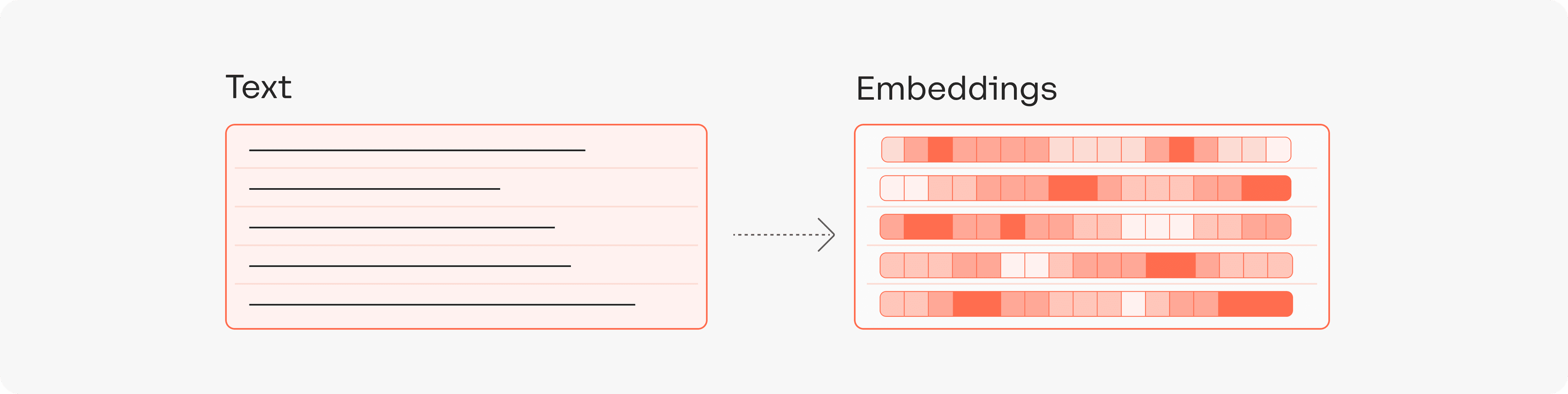
Cohere: Turning Text into Embeddings
Embeddings can be used by themselves when introduced into our own databases or use Cohere Semantic Search functionality to make searches. Cohere Semantic Search allows leveraging Cohere's search options to make content groupings (k-means-cluster) or search for content proximity based on a query.
An attractive feature of Cohere is that you can train your own representation models, assuming you have abundant examples of content (usually more than 500) and that they are well labeled.
To consider: it was noted that adding language models to power Google's search "represents the greatest advance in the last five years and one of the greatest advances in the history of Search." Microsoft also uses these models for each query in the Bing search engine.
BERT
If we prefer to run our own embeddings engine and have the computing power and patience, the BERT model can generate embeddings from our content. BERT is used in a wide variety of language-related tasks; It can perform sentiment analysis, answer questions, predict text, generate text, summarize, resolve polysemy.
OpenSearch Semantic Search
OpenSearch is a variant of ElasticSearch that remains Open Source. OpenSearch has introduced semantic search functionality. Its Semantic Search offering performs vector searches and allows indexing using external models such as TAS-B (publicly available on Huggingface).
Natural Language Processing (NLP)
Semantic search uses Artificial Intelligence and Natural Language Processing to understand and respond to search queries in a more natural and contextually aware manner. AI fuels the system's learning and adaptation ability, while NLP enables understanding and language generation. Together, they allow a more fluid and meaningful interaction with search systems and provide more relevant and accurate results.
Natural Language Processing (NLP) is a field of artificial intelligence that focuses on the interaction between systems and human language. Specifically, NLP refers to the ability of machines to understand, interpret, generate, and manipulate human language in a meaningful way.
The main goal of NLP is to enable computers to understand language in the same way humans do. This can involve tasks ranging from automatic translation (like Google Translate), to answering questions (like Siri or Alexa), to generating text (like automatic news summaries or writing assistants).
The relevance of NLP lies in its ability toefficiently analyze voice and text data, reconciling differences in dialects, slang, and common grammatical variations in everyday speech. This technology is widely used in various automated tasks, from virtual assistants to sentiment analysis systems, providing deeper insight into data and optimizing business operations.
Aplyca and AI developments
At Aplyca, we specialize in creating custom solutions that drive ROI and growth for organizations. Contact us to discover how we can help your company make the most of Generative AI and Natural Language Processing.