
Retrieval Augmented Generation (RAG): Guía Empresarial Completa y Mejores Practicas
INTELIGENCIA ARTIFICIAL.
Retrieval Augmented Generation (RAG) es una técnica para superar problemas. Combina LLMs con búsqueda inteligente para obtener datos de fuentes indexadas y gobernadas, generando resultados más precisos y relevantes.
Debido a su valor empresarial, el volumen del mercado global de RAG está en $1.92 mil millones y se proyecta que crezca a $10.20 mil millones para 2030, con una CAGR (Tasa de Crecimiento Anual) del 39.66% desde 2025 hasta 2030. El rápido crecimiento demuestra el valor clave de RAG para ayudar a las empresas a usar LLMs para construir aplicaciones de IA confiables, fácticas y seguras.
En esta guía, explicaremos por qué RAG es importante y sus componentes clave. Exploraremos casos de uso de RAG, opciones de plataforma y cómo Aplyca puede ayudar a construir un sistema RAG multi-tenant adaptado a sus necesidades.
¿Qué es RAG y por qué importa ahora?
Aunque el término "RAG" puede ser desconocido para muchos, ya se utiliza ampliamente en numerosas herramientas de IA con las que interactuamos regularmente. Cada vez que un LLM busca en la web (como la opción de búsqueda web de ChatGPT), escanea un PDF que sube o responde una pregunta usando un documento que se le proporciona, utiliza aumento de recuperación similar a RAG para generar respuestas.
RAG opera en tres etapas clave:
Retrieval (Recuperación): el sistema utiliza la consulta para buscar en una fuente externa confiable, como bases de datos, papers de investigación o bases de conocimiento empresarial. Este componente "retriever" identifica y extrae los fragmentos de información más relevantes.
Augment (Aumentación): el contexto recuperado se combina con la consulta original del usuario en un nuevo prompt más detallado.
Generation (Generación): este prompt aumentado se alimenta al LLM, que utiliza la información proporcionada para generar una respuesta fundamentada y contextualmente consciente.
RAG ayuda a los LLMs a fundamentar sus respuestas en fuentes de conocimiento autorizadas y predeterminadas, como los datos propietarios de su empresa. Sin esto, los LLMs tienden a dar información incorrecta cuando no conocen la respuesta literal, generar respuestas desactualizadas o crear detalles falsos por su cuenta, citando fuentes no confiables.
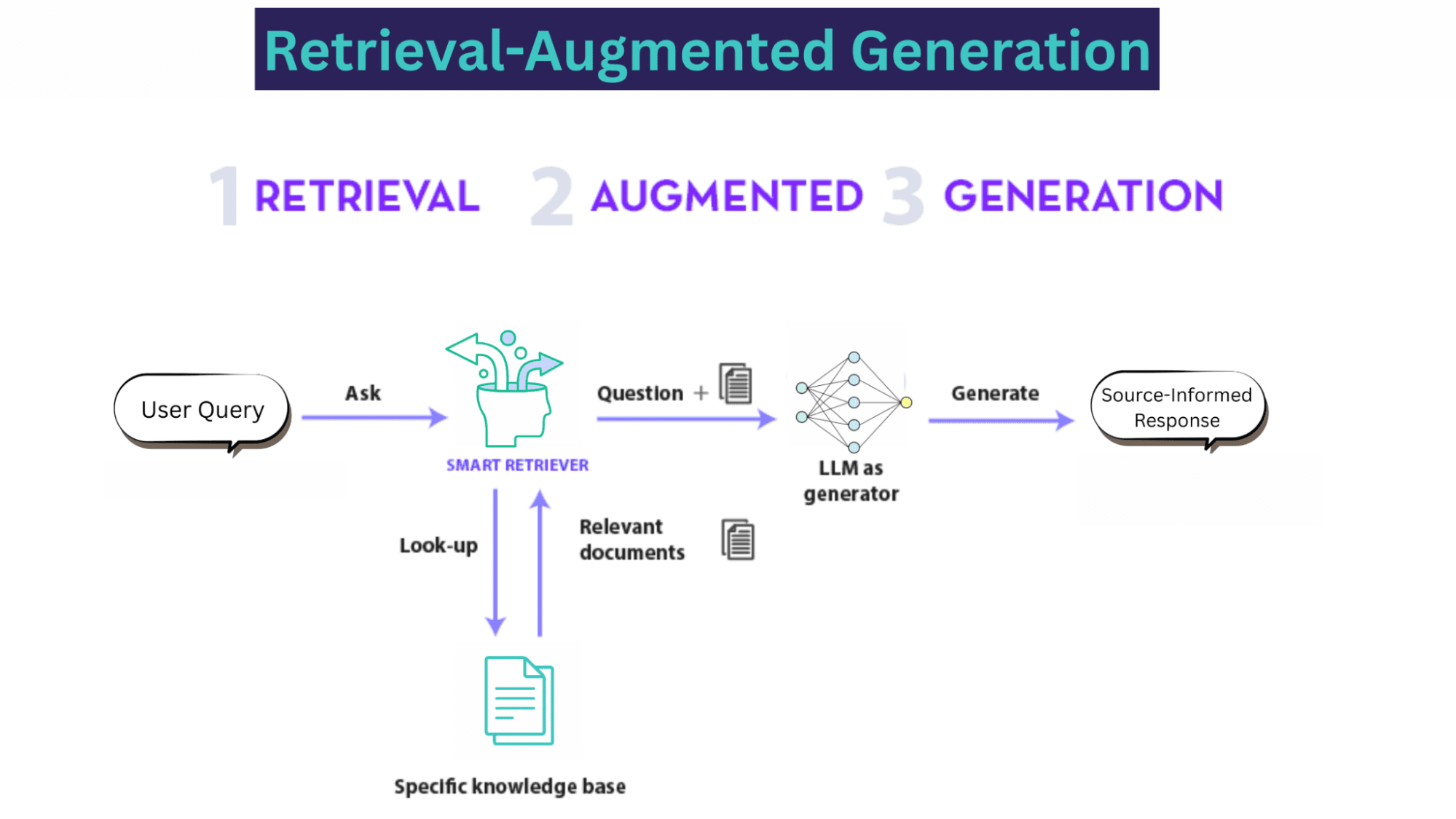
"Una instancia representativa del proceso RAG aplicado a respuesta de preguntas. | Fuente"
Sin embargo, con modelos avanzados como las últimas versiones de Google Gemini Pro y Claude Sonnet, la comunidad de IA está comenzando a cuestionar la relevancia de RAG en el futuro cercano. Abordemos el debate directamente.
¿Por qué todavía necesitamos RAG?
Los últimos modelos vienen con context windows más grandes, conocimiento más actualizado y mejores salvaguardas para prevenir que generen respuestas falsas o dañinas. Estas características a menudo llevan a los usuarios a pensar que RAG ya no es relevante.
Sin embargo, tales características introducen trade-offs en latencia, costo y rendimiento al procesar millones de tokens por consulta. Como resultado, los LLMs se vuelven más lentos y más costosos.
Por ejemplo, context windows más largos pueden permitir que los LLMs procesen más información simultáneamente. Sin embargo, la carga de procesamiento aumenta. Además, es desafiante verificar la información ya que el usuario carece de control sobre las fuentes que utiliza el modelo.
En contraste, RAG permite a las empresas aprovechar económicamente el conocimiento pre-entrenado de un LLM en una tarea específica de la industria. Los usuarios pueden construir una base de conocimiento cuidadosamente curada, permitiendo que el sistema RAG solo obtenga datos relevantes de ella, en lugar de buscar en toda la web.
Además, con la ayuda de agentic AI, los frameworks RAG pueden razonar qué base de conocimiento buscar según la consulta de un usuario. Como resultado, RAG permite a los LLMs utilizar nuevo conocimiento y cumplir con estándares regulatorios relevantes. Las empresas no tienen que pasar por toda una fase de re-entrenamiento o fine-tuning para actualizar un modelo a medida que cambian los requisitos del usuario.
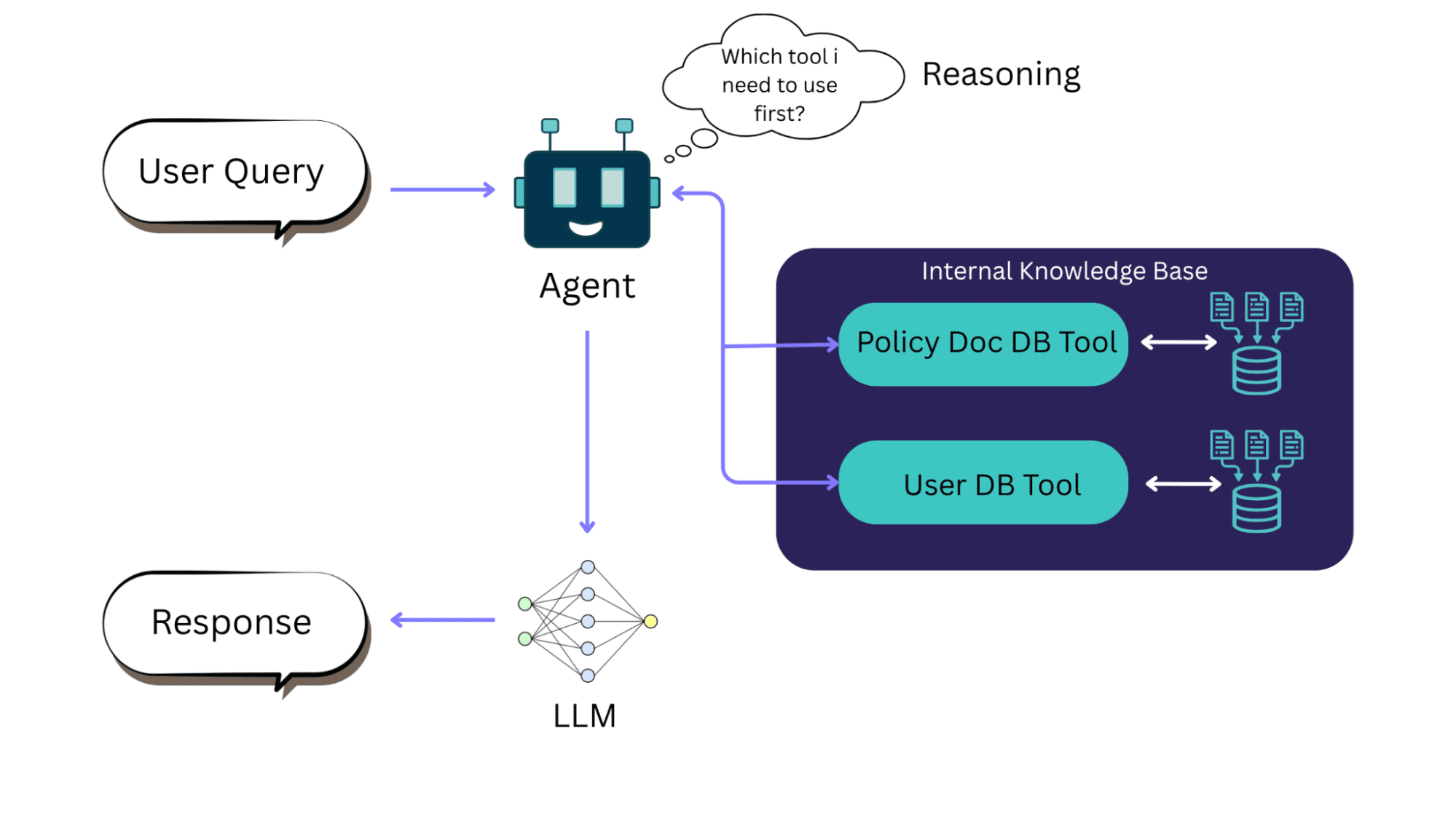
RAG con agente de IA | Fuente
Casos de Uso de RAG: Dónde genera impacto en la empresa
RAG no es una solución monolítica, sino que ayuda a impulsar valor en numerosas funciones empresariales. Las empresas pueden usar sus datos para convertir IA generativa genérica en herramientas orientadas al valor.
Experiencia Digital y del Cliente
El impacto inmediato de RAG está en transformar la experiencia digital y del cliente de una marca. Proporciona respuestas hiperpersonalizadas a consultas de usuarios, ya sea para preguntas pre-venta o soporte técnico 24/7. Lo hace recuperando contexto de una base de conocimiento específica construida a partir de especificaciones de productos, manuales y documentación interna de la empresa.
Además, las empresas pueden crear un feedback loop dinámico para registrar quejas de clientes, consultas, reseñas, tickets de soporte, y alimentar estos datos de vuelta al sistema RAG. Puede ayudar al sistema a volverse más inteligente y preciso con el tiempo a medida que más usuarios interactúan con él.
Integrar RAG con las plataformas de contenido que las empresas ya usan da vida a las experiencias digitales:
RAG con Adobe Experience Manager (AEM): AEM es una plataforma a gran escala para gestionar contenido digital y assets. Usar RAG con AEM permite a las empresas acceder a una enorme biblioteca de contenido y datos de usuario, lo que habilita experiencias personalizadas y conversacionales que se mantienen consistentes con el mensaje de la marca.
RAG con Contentful: es un headless CMS API-first que entrega contenido a varios canales. Integrar RAG con Contentful puede crear estrategias omnicanal que proporcionan respuestas inteligentes a través de websites, mobile apps y herramientas internas, todas extrayendo de la misma fuente de contenido confiable. En Aplyca usamos el mismo principio para crear una plataforma web omnicanal para Vanti Business Group, demostrando cómo una solución Contentful bien arquitecturada unifica un ecosistema digital complejo.
RAG con Ibexa DXP: Ibexa DXP gestiona catálogos de productos y contenido orientado a partners con un fuerte enfoque en escenarios B2B. RAG es poderoso aquí para construir soluciones de conversational commerce de próxima generación que ayudan a clientes B2B a navegar líneas de productos y recibir orientación experta a través de conversaciones automatizadas. En Aplyca, aprovechamos Ibexa DXP para modernizar el portal corporativo de Terpel, integrando chatbots, soporte multilingüe y módulos clave como georreferenciación para entregar una experiencia digital estable y escalable alineada con operaciones multi-país.
RAG con Payload CMS: Payload es un headless CMS enfocado en desarrolladores conocido por su flexibilidad y personalización profunda. Integrar RAG con Payload es perfecto para construir aplicaciones de IA vanguardistas y personalizadas donde los desarrolladores necesitan control granular para fusionar modelos de contenido únicos con características avanzadas de IA conversacional.
Producción y Gestión de Contenido
RAG acelera flujos de trabajo de contenido interno para empresas globales. Automatiza la actualización de bases de conocimiento creando resúmenes y FAQs de reportes largos y hace que la información sea actual y fácil de buscar. RAG también simplifica la publicación multilingüe usando terminología aprobada para traducciones, lo que asegura consistencia de marca y técnica en todos los idiomas.
Automatización de Procesos de Negocio
RAG agiliza operaciones internas automatizando la recuperación de conocimiento de documentos corporativos densos. Ayuda a equipos legales a revisar rápidamente miles de páginas de contratos o permite a oficiales de cumplimiento buscar reglas específicas como GDPR.
Además, actúa como un asistente virtual para todos los empleados, proporcionando respuestas precisas de manuales de RR.HH. y guías técnicas, ahorrando tiempo que de otro modo se gastaría buscando en sitios de intranet desordenados.
Construcción del Stack RAG: Guía de plataformas y frameworks empresariales
Seleccionar el stack tecnológico apropiado es una elección crucial que considera velocidad, flexibilidad, capital y control. Podemos ensamblar pipelines RAG usando servicios gestionados cloud-native o frameworks open-source flexibles.
Los principales proveedores cloud ofrecen servicios gestionados e integrados que aceleran significativamente el desarrollo y despliegue de aplicaciones RAG.
Por ejemplo, Amazon Web Services ofrece Knowledge Bases de Amazon Bedrock que conectan documentos corporativos (desde un bucket S3) a LLMs. Utiliza Amazon OpenSearch Service u otros vectores para indexación y proporciona infraestructura gestionada, autoscaling e integración fácil con otros servicios cloud.
De forma similar, Azure AI Search de Microsoft proporciona capacidades integradas de vector search que se conectan con Azure OpenAI, permitiéndole fundamentar modelos en sus propias fuentes de datos. Y Vertex AI Search de Google con suRAG Engine se conecta a datos empresariales en fuentes como BigQuery y Cloud Storage para mantener los outputs del modelo precisos y alineados con su información.
Alternativamente, podemos usar frameworks open-source para mayor flexibilidad (como construir pipelines RAG multi-cloud) y evitar vendor lock-in. Pueden incluir:
Orchestration Frameworks como LangChain y LlamaIndex para ayudar a estructurar el pipeline RAG, desde cargar documentos hasta hacer prompting al LLM.
Cloud vs. Agnóstico: El dilema empresarial
La elección entre un stack cloud-native gestionado y una solución open-source es una decisión estratégica crítica porque no hay una respuesta única para todos.
La tabla a continuación muestra los factores críticos a considerar al elegir entre los dos:
Factor | Cloud-Native | Agnóstico / Open-Source |
Time-to-Market | Más rápido. Servicios gestionados estrechamente integrados reducen enormemente el tiempo de desarrollo y despliegue | Más lento. Requiere más tiempo para setup, integración y configuración manual de componentes individuales |
Estructura de Costos | Basado en consumo (OpEx). Pricing predecible pay-as-you-go, pero puede volverse costoso a gran escala | Basado en infraestructura y talento (CapEx/OpEx). Costos directos de software más bajos, pero requiere inversión significativa en talento interno especializado y gestión de infraestructura |
Flexibilidad y Control | Menos flexible. Limitado al ecosistema y opciones de componentes del proveedor. La personalización puede estar restringida | Altamente flexible. Libertad completa para mezclar y combinar los mejores modelos, bases de datos y frameworks. Sin vendor lock-in |
Expertise In-House | Requisito más bajo. Abstrae mucha de la gestión compleja de infraestructura, requiriendo menos conocimiento especializado de MLOps/DevOps | Requisito más alto. Demanda un equipo interno fuerte con expertise profunda en DevOps, MLOps, Kubernetes e ingeniería de datos |
Mantenimiento y Escalamiento | Gestionado. El proveedor cloud maneja parches de seguridad, actualizaciones y scaling, asegurando alta disponibilidad y confiabilidad | Auto-gestionado. Su equipo es completamente responsable de todo el mantenimiento, seguridad y operaciones de scaling |
Mejor para | Empresas que priorizan velocidad, facilidad de uso y usar una inversión cloud existente para obtener una solución confiable al mercado rápidamente | Empresas con necesidades de personalización únicas, un equipo técnico interno fuerte y una estrategia para evitar vendor lock-in a toda costa |
Técnicas Avanzadas de RAG
A medida que las organizaciones maduran más allá de la recuperación básica, las arquitecturas Advanced RAG apuntan a mejorar relevancia, profundidad de razonamiento y trazabilidad. Estas técnicas combinan innovaciones de búsqueda, teoría de grafos y razonamiento multi-agente para crear sistemas de IA que entienden contexto en lugar de simplemente recuperarlo.
Hybrid y Multi-Stage Retrieval
Los datos empresariales modernos son heterogéneos, mezclando bases de datos estructuradas, documentos y medios. Una estrategia hybrid retrieval fusiona búsqueda simbólica (BM25, keyword) con dense vector search (semantic embeddings).
Lexical Filter: Búsqueda rápida de keywords o metadata.
Dense Retrieval: Los vectores semánticos clasifican la proximidad contextual.
Cross-Encoder Re-ranking: Un transformer más pequeño re-puntua los mejores resultados para precisión semántica.
Este pipeline de tres niveles típicamente mejora la precisión contextual en 15-25% sin overhead significativo de latencia.
HyDE (Hypothetical Document Embeddings)
Hypothetical Document Embeddings (HyDE) mejora la recuperación generando una respuesta ideal hipotética a una consulta antes de buscar. Este "pseudo-document" luego se incrusta y se usa para recuperación, llevando a mayor recall, particularmente en datasets dispersos o cuando la terminología de origen difiere.
HyDE es especialmente valioso para bases de conocimiento empresariales, que a menudo contienen datos semi-estructurados como políticas, FAQs y PDFs, ya que efectivamente cierra brechas de vocabulario. Se integra sin problemas con OpenSearch + AWS Bedrock o retrievers de LangChain. Aunque introduce un ligero aumento de latencia de aproximadamente 100-200 ms, este es un pequeño trade-off por la notable mejora en la calidad del recall.
Graph RAG
Graph RAG utiliza knowledge graphs para representar entidades (ej., personas, productos, regulaciones) y sus relaciones, almacenando esta información en bases de datos como Neo4j, AWS Neptune o engines compatibles con RDF. Este enfoque permite que la recuperación navegue paths de grafos complejos en lugar de depender de texto plano.
Capacidad | Beneficio |
Entity Linking | Previene duplicación y resuelve ambigüedades de alias |
Relationship Traversal | Habilita razonamiento avanzado multi-hop, permitiendo consultas como "¿Quién aprobó qué y por qué?" |
Provenance Tracking | Facilita rastrear respuestas de vuelta a sus nodos originales para cumplimiento y auditoría |
Graph RAG es particularmente valioso para aplicaciones como auditorías regulatorias, trazabilidad de supply-chain, investigación farmacéutica y gestión de taxonomías corporativas. Para un fundamento aún más robusto, combina contexto de grafo con embeddings vectoriales en un enfoque híbrido (Graph + RAG).
Multi-Vector y Late-Interaction Models
A diferencia del RAG tradicional, que incrusta un documento completo como un único vector denso, multi-vector retrieval (ej., ColBERT, CoVeR, ANCE) codifica individualmente cada oración o token. Este enfoque habilita late interaction scoring, donde los vectores de consulta y documento se comparan después de la fase de recuperación inicial.
Los beneficios incluyen mejor manejo de documentos complejos, cobertura semántica mejorada y mayor precisión, lo que entrega mayor precisión para question answering sobre textos especializados como documentos legales o técnicos.
Reranking y Fusion Retrieval
Para repositorios grandes, la recuperación inicial a menudo mezcla resultados relevantes y ruidosos. Una etapa de reranking aplica un modelo cross-encoder (ej., BGE-Reranker, MonoT5) para refinar el ordenamiento. Fusion retrieval agrega múltiples retrievers (denso, léxico, grafo) a través de votación ponderada o reciprocal rank fusion (RRF).
Este ensamble híbrido mejora consistentemente la precisión Top-k (la probabilidad de que la evidencia correcta aparezca en los primeros k resultados) en 20-40%.
Memory-Augmented RAG
Las empresas que usan copilots conversacionales requieren persistencia de sesión. Memory-Augmented RAG aborda esto almacenando interacciones pasadas como embeddings recuperables, creando una memoria semántica de corto plazo.
Memory-Augmented RAG incluye agentes de customer-support que necesitan mantener contexto de caso, asistentes de onboarding que recuerdan temas previos y copilots de marketing personalizados que recuerdan el historial del usuario.
Agentic RAG (Capa de Orquestación de IA)
La frontera más nueva fusiona RAG con razonamiento autónomo. Agentic RAG permite que el modelo planifique recuperaciones multi-paso, verifique resultados y llame herramientas o APIs dinámicamente. Impulsado por orchestration frameworks (LangGraph, DSPy, AutoGen o AWS Bedrock Agents), estos sistemas pueden:
Formular sub-consultas.
Recuperar y validar hechos.
Sintetizar insights multi-documento.
Producir una cadena de razonamiento auditable.
El impacto empresarial incluye transformar la recuperación estática de conocimiento en workflows dinámicos de soporte de decisiones, mejorar la explicabilidad registrando cada paso de razonamiento y su fuente, y facilitar orquestación gobernada cross-system (CRM, CMS, ERP).
Mejores Prácticas de RAG para Preparación de Producción
La transición a un sistema RAG listo para producción requiere arquitectura escalable, evaluación continua y seguridad fuerte desde el inicio. Para poner en marcha un sistema RAG, considere estas prácticas:
Comience Simple, Itere Incansablemente: no intente implementar un pipeline complejo multi-agente desde el día uno. Comience con un pipeline básico (embed-docs + BM25 o single-vector retriever + LLM) y estabilícelo. Luego agregue complejidad incrementalmente (rerankers, hyde, etc.) según necesidad.
Siempre Mida (Evaluación Continua): implemente un framework de evaluación fuerte desde el inicio. Rastree puntajes de recuperación y respuesta en consultas retenidas. Versione sus índices y prompts para que pueda revertir si la calidad cae. Use herramientas como DeepEval, Ragas o pruebas internas de forma continua.
Planifique para Multilingüe y Multi-Tenancy Temprano: si su empresa sirve múltiples idiomas o clientes distintos, diseñe para ello desde el principio. Para soporte multilingüe, considere usar modelos de embedding multilingües o mantener índices separados para cada idioma. Para multi-tenancy (una plataforma SaaS), planifique aislamiento de datos e indexación per-tenant desde el inicio. Use buckets S3 por tenant de AWS y encriptación para aislar datos. Intentar agregar esto después puede requerir re-arquitectura costosa.
Seguridad y Cumplimiento Primero: necesita tratar RAG como cualquier otro proyecto de datos sensibles y encriptar todos los vector stores en reposo, usar rotación de llaves e implementar IAM estricto para que solo roles autorizados puedan consultar o indexar datos. Asegure que sus logs de RAG sean auditables (qué documentos fuente se usaron para cada respuesta). Todos los pipelines de contenido deben sanitizar input y output (si inputs de usuario se usan en prompts).
Partner para Expertise: dada la complejidad, considere trabajar con un especialista como Aplyca. Desplegar un sistema RAG robusto involucra IA, DevOps, ingeniería de datos y seguridad, por lo que tener un partner experimentado puede ayudar a acelerar el progreso y hacer cumplir mejores prácticas.
Cómo Aplyca entrega un pipeline RAG multilingüe y multi-tenant para una empresa global
Construir, desplegar y mantener un pipeline RAG avanzado de grado empresarial es más una hazaña de ingeniería que requiere expertise en arquitectura de datos, infraestructura cloud, DevOps y seguridad.
El Desafío
Considere una firma global de servicios financieros con oficinas en América del Norte y Europa. Quieren dar a sus asesores respuestas en tiempo real y conformes de una vasta y constantemente cambiante colección de reportes internos, notas de analistas y documentos regulatorios. Pero enfrentan algunos desafíos:
Seguridad de Datos: el sistema debe hacer cumplir segregación estricta de datos. Los asesores trabajando en wealth management no deberían acceder información de investment banking
Escalabilidad: necesita funcionar bien incluso cuando miles de asesores hacen preguntas al mismo tiempo
Soporte Multilingüe: necesita servir tanto a equipos de habla inglesa como española con alta precisión.
La Solución Aplyca
En Aplyca resolvemos este tipo de problemas. Hacemos la arquitectura de una solución que es segura, escalable y resiliente por diseño usando nuestra profunda expertise en DevOps y como AWS Partner.
Diseño Compliance-First: diseñamos un pipeline RAG multi-tenant seguro. Usando servicios AWS, implementamos un modelo de gobernanza de datos con aislamiento avanzado de datos para que los datos de cada división se mantengan separados, tanto lógica como físicamente. De esta manera, nadie puede acceder a la información del otro equipo, lo que mantiene todo conforme y seguro.
Excelencia DevOps y MLOps: con expertise DevOps, construimos un pipeline MLOps automatizado para el sistema RAG con infrastructure y código (IaC) para entornos repetibles, CI/CD para los componentes de IA y monitoreo y logging fuertes.
Construido para Crecer: usando servicios AWS escalables y funciones sin servidor, el sistema está diseñado para manejar grandes cargas de trabajo desde el inicio. Puede soportar automáticamente miles de usuarios al mismo tiempo sin desacelerarse, proporcionando una experiencia fluida para cada asesor.
Este sistema transforma el conocimiento especializado de la empresa en un activo valioso. Los asesores se benefician de respuestas rápidas y confiables, mejorando su productividad y toma de decisiones. Consecuentemente, la firma gana una ventaja competitiva mientras mantiene seguridad y cumplimiento regulatorio.
¿Listo para hacer que el conocimiento de su empresa sea verdaderamente inteligente?
Aplyca diseña e implementa arquitecturas de experiencia digital potenciadas por RAG en AWS y plataformas composables como Contentful, Ibexa DXP, PayloadCMS y Adobe AEM.
Contáctenos para discutir cómo RAG puede impulsar su próxima generación de experiencias digitales impulsadas por IA.