
Búsqueda Semántica - Un nuevo paso en la Experiencia Digital
EXPERIENCIA DE USUARIO, TECNOLOGÍA DE EXPERIENCIA.
Cuando utilizamos sitios web y hacemos clic en la pequeña lupa para iniciar una búsqueda, nos enfrentamos a tres posibilidades: tener suerte y encontrar lo que buscamos, obtener cero resultados porque nuestra palabra clave no existe, o recibir cientos de resultados irrelevantes cuando incluimos varias palabras.
El interés en la búsqueda semántica ha resurgido debido al entusiasmo generado por los avances recientes en la Inteligencia Artificial Generativa (Generative AI) y a cierta idealización de sus capacidades. Su potencial radica en permitir experiencias de búsqueda mucho más satisfactorias en plataformas web y e-commerce privadas, utilizando tecnologías que antes eran exclusivas de los gigantes de la tecnología, como Google, Netflix o Spotify.
¿Qué es la búsqueda semántica?
La "semántica" es una disciplina lingüística que se enfoca en el estudio del significado y la comprensión del lenguaje. Analiza cómo las palabras, frases y oraciones representan diferentes conceptos y significados en distintos contextos.
Las búsquedas semánticas tratan de capturar el significado y la intención de una búsqueda en lugar de simplemente coincidir con las palabras clave.
Bolsas de palabras
Cuando usamos un buscador como Elastic Search y Solr se usa un proceso de búsqueda de tipo bolsa de palabras (bag-of-words). Esta bolsa está creada al ignorar palabras comunes (stop-words), sacan la raíz de las palabras (stemming) y guardarlas en un índice, conocido como un vector disperso. Al hacer una consulta, se usan algoritmos que encuentran las palabras y les asignan un puntaje para saber cómo ordenar los resultados. Los algoritmos ranquean de acuerdo a qué tan presente está la palabra en el documento encontrado vs. qué tan escasa o abundante es en el resto de documentos. Por ejemplo, si aparece en el documento encontrado varias veces, y es escasa en los demás documentos, tenemos un resultado ganador. Los algoritmos en sí son relativamente fáciles de entender y puede ser interesante explorar la historia y el funcionamiento de algoritmos como TF-IDF y BM25 aunque no cambian de forma importante el modelo de búsqueda.
Las búsquedas tipo bolsa de palabras son muy efectivas cuando hay una correlación fuerte entre lo que buscamos y el índice del documento. Si buscamos la palabra perro, y el documento la tiene de manera protagónica frente a los demás: ¡maravilloso!. Por eso este tipo de modelo es ideal para búsquedas directas, precisas, idealmente de pocos términos. Al tener muchos más términos, con sinónimos, derivaciones de palabras y otros significados implícitos, llegamos al temido “cero resultados de búsqueda”.
Las búsquedas semánticas
Las búsquedas semánticas permiten encontrar similitudes relevantes en un conjunto de datos. En lugar de buscar coincidencias exactas de palabras clave – como en una búsqueda de bolsa de palabras – las búsquedas semánticas permiten a los motores de búsqueda identificar elementos que son semánticamente similares a la consulta de búsqueda del usuario.
Para lograr búsquedas vectoriales en que una palabra o contenido es representada con su significado son necesarios espacios vectoriales y embeddings (incrustaciones). En términos sencillos, un embedding es una representación numérica (vector) de un objeto de texto (como una palabra o una frase). Estos embeddings se generan de tal manera que palabras o frases con significados similares están más cerca entre sí en el espacio vectorial. La magia ocurre con técnicas de procesamiento de lenguaje natural y aprendizaje automático, que se entrenan con grandes conjuntos de datos para aprender las sutilezas del lenguaje y del contenido con el cual fueron entrenados.
El motor de búsqueda transforma la consulta del usuario en un vector (también conocido como embedding), y busca en su base de datos otros vectores que sean similares. La similitud se mide generalmente usando una métrica de distancia en el espacio vectorial, y devuelven resultados ordenados por similitud sin que tengan que coincidir exactamente.
Las búsquedas vectoriales son capaces de captar las sutilezas y la semántica del lenguaje logrando búsquedas más pertinentes. Por ejemplo, una búsqueda vectorial sería capaz de entender que una consulta de búsqueda para "perro" puede devolver resultados sobre “animales”, “Teckel”, “labrador”.
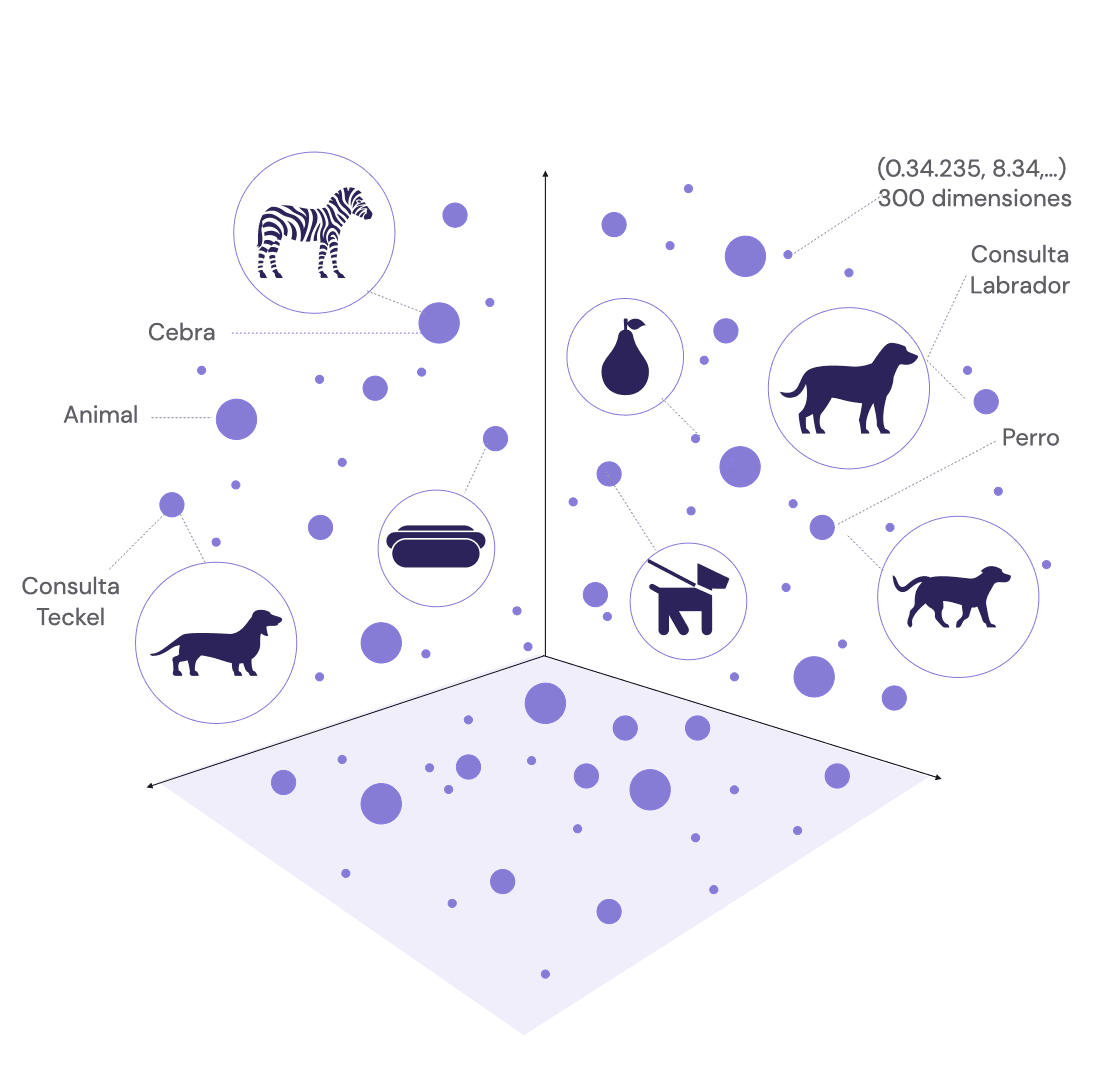
Figura 1: Representación vectorial simplificada de varios conceptos.
Los motores vectoriales ayudan a guardar grandes cantidades de datos para entender el contexto, la intención del usuario y las relaciones entre diferentes conceptos, todo lo cual es crucial para proporcionar resultados de búsqueda precisos y personalizados.
En 2023 han empezado a tener protagonismo bases de datos vectoriales para almacenar y buscar sobre vectores. Algunas de ellas como Pinecone y Weaviate tienen modelos de búsqueda híbridos, donde la misma búsqueda se hace con bag-of-words y semántica, para luego poder combinar los resultados.
Bases de datos vectoriales para búsqueda semántica
Las bases de datos vectoriales permiten almacenar y buscar contenido semántico. Aunque no son la única manera de buscar están teniendo un incremento de interés de las comunidades así como inversión de fondos para expandir su presencia en el mercado.
Herramienta | Usuarios destacados | Características BD | Gestión | Filtrado tipo SQL | Búsqueda de texto completo |
|---|---|---|---|---|---|
Chroma | N/A | ✓ | ✓ | ✓ | 𐄂 |
Milvus | ebay, Walmart | ✓ | 𐄂 | ✓ | 𐄂 |
Pinecone | Shopify, Gong | ✓ | 𐄂 | ✓ | 𐄂 |
Vespa | Yahoo, Spotify | ✓ | ✓ | ✓ | ✓ |
Weaviate | N/A | ✓ | ✓ | ✓ | ✓ |
Tabla 1: Tomado de la conferencia por Josh Tobin. Publicada el 9 de mayo de 2023.
Pinecone
Es un servicio que se centra en la búsqueda vectorial semántica, comúnmente usada para integrar funcionalidades de aprendizaje automático en aplicaciones. Pinecone facilita la indexación y búsqueda de vectores de alta dimensión a gran escala. Es especialmente útil en contextos que requieren representaciones vectoriales para recuperar información.
Weaviate
Es un sistema de base de datos que combina funciones semánticas y vectoriales. Utiliza técnicas de aprendizaje automático para la búsqueda y clasificación semántica de datos. Weaviate destaca por su capacidad para realizar búsquedas contextuales y semánticas, gracias a su motor de clasificación basado en vectores.
Chroma
Es una base de datos de embeddings de código abierto que facilita la creación de aplicaciones LLM al hacer que los conocimientos, los hechos y las habilidades sean fácilmente integrables. Permite almacenar embeddings y sus metadatos, incrustar documentos y consultas, y buscar embeddings.
Milvus
Es una base de datos de vectores de código abierto diseñada para búsquedas de similitud a gran escala. Permite trabajar con varias métricas de distancia, incluyendo la distancia euclidiana y la similitud del coseno. También ofrece opciones para personalizar la indexación y es compatible con aplicaciones de aprendizaje automático. Esta versatilidad lo convierte en una excelente opción para tareas que requieren representaciones vectoriales para la recuperación de información.
Vespa
Es un motor de búsqueda y recuperación de información en tiempo real, creado por Yahoo. Su fortaleza radica en el manejo de búsquedas tanto en texto como en representaciones vectoriales de datos. Vespa puede indexar grandes volúmenes de datos y entregar resultados de búsqueda de manera eficiente. Además, permite la definición y cálculo de funciones personalizadas para clasificar documentos al momento de la consulta.
Nomic Atlas
Está en una categoría especial. Creado por Nomic.ai tiene una aproximación muy interesante: combina un generador de embeddings, una base de datos semántica y un visualizador online para millones de datos. Visualiza e interactúa con grandes conjuntos de datos, colabora en su limpieza y etiquetado, desarrolla aplicaciones de alta disponibilidad con búsqueda semántica y comprende el espacio latente de los modelos de IA.
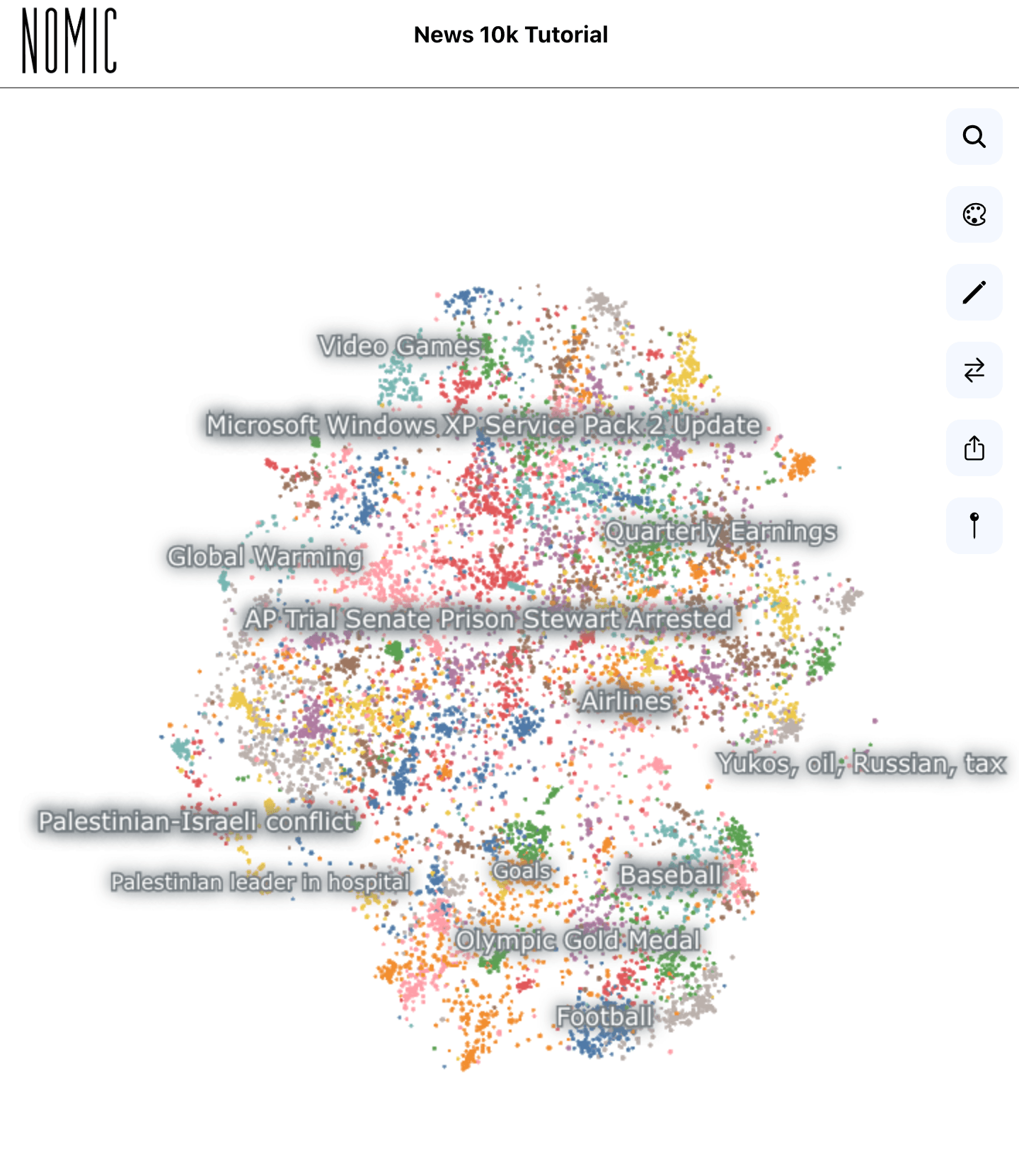
NOMIC, Data Exploration.
Imaginar la proximidad semántica de dos contenidos es difícil pero su herramienta de visualización resume el resultado de los vectores de embeddings en un espacio bi-dimensional. Las demos de Nomic Atlas son impresionantes, agrupando millones de tweets sin afectar el performance de la máquina que los ve. La plataforma está evolucionando rápido y Nomic tiene un equipo fuerte de desarrollo. En Junio de 2023, el visualizador funciona bien en desktop, pero en móvil aún es muy limitado. Su plan gratuito permite explorar datos fácilmente, y su documentación tiene buenos ejemplos para implementar.
Semantic Embeddings, la magia de las relaciones semánticas
Los embeddings o incrustaciones semánticas son una forma de representar palabras como vectores en un espacio de alta dimensionalidad, donde las palabras con significados similares se encuentran cerca unas de otras. Esta técnica se ha utilizado en tareas de procesamiento del lenguaje natural, cómo clasificación de texto, recuperación de información y traducción de idiomas.
OpenAI Embeddings
El servicio de OpenAI Embeddings, que por detrás usa el modelo text-embedding-ada-002 es una opción atractiva en términos de precio y calidad. Aunque OpenAI se conoce ampliamente por ChatGPT, el servicio de embeddings usa un motor mucho menos poderoso que GPT-4, pero considerablemente potente y muy eficiente en términos de precio.
Cohere Embeddings
Cohere es una innovadora firma canadiense que ha creado sus propios motores de Generación, Clasificación y Búsqueda Semántica. Cohere tiene motores de embeddings multi-idioma con auto detección así como de un solo idioma con diferentes capacidades.
Cohere: Convirtiendo texto en embeddings
Los embeddings pueden usarse por sí mismos al introducirlos en nuestras propias bases de datos o usar la funcionalidad de Cohere Semantic Search para hacer búsquedas. Cohere Semantic Search permite aprovechar las opciones de búsqueda de Cohere para hacer agrupaciones de contenido (k-means-clustering) o buscar proximidad de contenidos a partir de una consulta.
Un factor atractivo de Cohere es que se pueden entrenar modelos de representación propios, asumiendo que se tienen ejemplos abundantes de contenido (usualmente más de 500) y que están bien etiquetados.
Para considerar: se señaló que agregar modelos de lenguaje para potenciar la búsqueda de Google "representa el mayor avance en los últimos cinco años y uno de los mayores avances en la historia de la Búsqueda". Microsoft también usa estos modelos para cada consulta en el motor de búsqueda de Bing.
BERT
Si preferimos correr nuestro propio motor de embeddings y contamos con la capacidad de cómputo y la paciencia, el modelo de BERT puede generar embeddings a partir de nuestro contenido. BERT se utiliza en una amplia variedad de tareas relacionadas con el lenguaje; Puede hacer análisis de sentimientos, respuesta a preguntas, agrupación (cluster) de contenidos, predicción de texto, generación de texto y mucho más.
OpenSearch Semantic Search
OpenSearch es una variante de ElasticSearch que se mantiene como Open Source. OpenSearch ha introducido funcionalidades de búsqueda semántica. Su oferta de Semantic Search hace búsquedas vectoriales y permite hacer una indexación usando modelos externos como TAS-B (públicamente disponible en Huggingface).
Sobre Natural Language Processing (NLP)
La búsqueda semántica utiliza la Inteligencia Artificial y el Procesamiento del Lenguaje Natural para comprender y responder a las consultas de búsqueda de una manera más natural y contextualmente consciente. La IA alimenta la capacidad de aprendizaje y adaptación del sistema, mientras que el NLP permite la comprensión y generación de lenguaje. Juntos, permiten una interacción más fluida y significativa con los sistemas de búsqueda y proporcionan resultados más relevantes y precisos.
El Procesamiento del Lenguaje Natural (PLN o NLP, por sus siglas en inglés) es un campo de la inteligencia artificial que se centra en la interacción entre sistemas y lenguaje humano. Específicamente, PLN se refiere a la capacidad de las máquinas para comprender, interpretar, generar y manipular el lenguaje humano de una manera valiosa.
El objetivo principal del PLN es permitir que las computadoras comprendan el lenguaje de la misma manera que los humanos lo hacen. Esto puede implicar tareas que van desde la traducción automática (como Google Translate), hasta la respuesta a preguntas (como Siri o Alexa), pasando por la generación de texto (como los resúmenes automáticos de noticias o los asistentes de escritura).
La relevancia del PLN radica en su habilidad para analizar eficientemente los datos de voz y texto, reconciliando diferencias en dialectos, jerga y variaciones gramaticales comunes en el habla cotidiana. Esta tecnología es ampliamente empleada en distintas tareas automatizadas, desde asistentes virtuales hasta sistemas de análisis de sentimientos, proporcionando una visión más profunda de los datos y optimizando las operaciones de las empresas.
Aplyca y los desarrollos con IA
En Aplyca nos especializamos en crear soluciones a medida que impulsan el ROI y el crecimiento de las organizaciones. Contáctenos para descubrir cómo podemos ayudar a su empresa a aprovechar al máximo el poder de la IA Generativa y el Procesamiento del Lenguaje Natural.